README file for net-snmp Version: 5.9
DISCLAIMER
The Authors assume no responsibility for damage or loss of system
performance as a direct or indirect result of the use of this
software. This software is provided "as is" without express or
implied warranty.
TABLE OF CONTENTS
Disclaimer
Table Of Contents
Introduction
* Supported Architectures
Availability
Web Page
* Installation
Copying And Copyrights
* Frequently Asked Questions
Helping Out
* Code Update Announcements
* Mailing Lists
Agent Extensibility
Example Agent Configuration and Usage
Configuration
Submitting Bug Reports
Closing
Thanks
* = Required Reading.
INTRODUCTION
This package was originally based on the CMU 2.1.2.1 snmp code. It
has been greatly modified, restructured, enhanced and fixed. It
hardly looks the same as anything that CMU has ever released. It
was renamed from cmu-snmp to ucd-snmp in 1995 and later renamed from
ucd-snmp to net-snmp in November 2000.
This README file serves as a starting place to learn about the
package, but very little of the documentation is contained within
this file. The FAQ is an excellent place to start as well.
Additionally, there are a bunch of README files for specific
architectures and specific features. You might wish to look at some
of these other files as well.
SUPPORTED ARCHITECTURES
Please see the FAQ for this information.
Please let us know if you compile it on other OS versions and it
works for you so we can add them to the above list.
Porting: Please! read the PORTING file.
Also note that many architecture have architecture specific README
files, so you should check to see if there is one appropriate to
your platform.
AVAILABILITY
Download:
- http://www.net-snmp.org/download/
Web page:
- http://www.net-snmp.org/
Project Wiki:
- http://www.net-snmp.org/wiki/
Sourceforge Project page:
- http://sourceforge.net/projects/net-snmp
The old ucd-snmp.ucdavis.edu web site and ftp server is now
offline and should not be accessed any longer.
WEB PAGES
http://www.net-snmp.org/http://sourceforge.net/projects/net-snmphttp://www.net-snmp.org/wiki/
INSTALLATION
See the INSTALL file distributed with this package.
COPYING AND COPYRIGHTS
See the COPYING file distributed with this package.
FREQUENTLY ASKED QUESTIONS
See the FAQ file distributed with this package.
This is also available on the project Wiki at
http://www.net-snmp.org/wiki/index.php/FAQ
so that the wider Net-SNMP community can help maintain it!
HELPING OUT
This is a project worked on by people around the net. We'd love
your help, but please read the PORTING file first. Also, subscribe
to the net-snmp-coders list described below and mention what you're
going to work on to make sure no one else is already doing so!
You'll also need to keep up to date with the latest code snap shot,
which can be obtained from CVS using the information found at
http://www.net-snmp.org/cvs/.
Contributions to the Net-SNMP source code in any form are greatly
appreciated. We expect the parties providing such contributions to
have the right to contribute them to the Net-SNMP project or that
the parties that do have the right have directed the person
submitting the contribution to do so. In addition, all contributors
need to be aware that if the contribution is accepted and
incorporated into the Net-SNMP project, it will be redistributed
under the terms of the license agreement used for the entire body of
work that comprises the Net-SNMP project (see the COPYING file for
details). If this license agreement ever changes the contribution
will continue to be released under any new licenses as well. Thank
you, in advance, for your gracious contributions.
CODE UPDATE ANNOUNCEMENTS
See the NEWS file and the ChangeLog file for details on what has
changed between releases.
We hate broadcasting announce messages to other mailing lists and
newsgroups, so there is a mailing list set up to handle release
announcements. Any time we put new software out for ftp, we'll mail
this fact to net-snmp-announce@lists.sourceforge.net. See the
MAILING LISTS section described below to sign up for these
announcements.
We will post new announcements on a very infrequent basis to the
other channels (the other snmp mailing lists and newsgroups like
comp.protocols.snmp), but only for major code revisions and not for
bug-fix patches or small feature upgrades.
MAILING LISTS
The lists:
A number of mailing lists have been created for support of the project:
The main ones are:
net-snmp-announce@lists.sourceforge.net -- For official announcements
net-snmp-users@lists.sourceforge.net -- For usage discussions
net-snmp-coders@lists.sourceforge.net -- For development discussions
The -coders list is intended for discussion on development of code
that will be shipped as part of the package. The -users list is
for general discussion on configuring and using the package,
including issues with coding user-developed applications (clients,
managers, MIB modules, etc).
Please do *NOT* send messages to both -users and -coders lists.
This is completely unnecessary, and simply serves to further
overload (and annoy) the core development team. If in doubt,
just use the -users list.
The other lists of possible interest are:
net-snmp-cvs@lists.sourceforge.net -- For cvs update announcements
net-snmp-bugs@lists.sourceforge.net -- For Bug database update announcements
net-snmp-patches@lists.sourceforge.net -- For Patch database update announcements
Please do NOT post messages to these lists (or to the announce list above).
Bug reports and Patches should be submitted via the Source Forge tracker
system. See the main project web pages for details.
To subscribe to any of these lists, please see:
http://www.net-snmp.org/lists/
Archives:
The archives for these mailing lists can be found by following links at
http://www.net-snmp.org/lists/
AGENT EXTENSIBILITY
The agent that comes with this package is extensible through use of
shell scripts and other methods. See the configuration manual pages
(like snmpd.conf) and run the snmpconf perl script for further details.
You can also extend the agent by writing C code directly. The agent
is extremely modular in nature and you need only create new files,
re-run configure and re-compile (or link against its libraries). No
modification of the distributed source files are necessary. See the
following files for details on how to go about this:
http://www.net-snmp.org/tutorial-5/toolkit/,
agent/mibgroup/examples/*.c
Also, see the local/mib2c program and its README file for help in
turning a textual mib description into a C code template.
We now support AgentX for subagent extensibility. The net-snmp
agent can run as both a master agent and a subagent. Additionally,
a toolkit is provided that enables users of it to easily embed a
agentx client into external applications. See the tutorial at
http://www.net-snmp.org/tutorial-5/toolkit/ for an example of how
go about doing this.
CONFIGURATION
See the man/snmp.conf.5 manual page.
For the agent, additionally see the man/snmpd.conf.5 manual page.
For the snmptrapd, see the man/snmptrapd.conf.5 manual page.
You can also run the snmpconf perl script to help you create some of
these files.
SUBMITTING BUG REPORTS
Important: *Please* include what version of the net-snmp (or
ucd-snmp) package you are using and what architecture(s) you're
using, as well as detailed information about exactly what is wrong.
To submit a bug report, please use the web interface at
http://www.net-snmp.org/bugs/. It is a full-fledged
bug-tracking system that will allow you to search for already
existing bug reports as well as track the status of your report as
it is processed by the core developers.
If you intend to submit a patch as well, please read the PORTING
file before you do so and then submit it to
http://www.net-snmp.org/patches/.
CLOSING
We love patches. Send some to us! But before you do, please see
the 'PORTING' file for information on helping us out with the
process of integrating your patches (regardless of whether its a new
feature implementation or a new port).
Also, We're interested if anyone actually uses/likes/hates/whatever
this package... Mail us a note and let us know what you think of it!
Have fun and may it make your life easier,
The net-snmp developers
THANKS
This project has been graciously supported by a long list of people
(too long to keep roperly up to date). To them we owe our deepest
thanks (and you do too!). Please see the git log or ChangeLog file,
where the core developers are careful to have (hopefully always)
pointed out where patches have come from.
Create the virtual machine and installs all the needed packages:
user@host> vagrant up # It can takes several hours depending on your internet connection
Connect to the vm with:
user@host> vagrant ssh
Your android build distribution is ready to be use:
vagrant@guest> # do whatever you want
Real World Android Build
user@host> vagrant up # Creates and Configure the VM
user@host> vagrant ssh # Connects to the VM
vagrant@guest> mkdir /mnt/android
vagrant@guest> cd /mnt/android # Move to android directory
vagrant@guest:android> repo init -u https://android.googlesource.com/platform/manifest -b android-4.4.4_r2
vagrant@guest:android> repo sync \
# It can takes several hours depending on your internet connection
vagrant@guest:android> source build/envsetup.sh # Set-up compilation environment
vagrant@guest:android> lunch 1 # Selects the generic arm build
vagrant@guest:android> make -j4 \
# It can takes several hours depending on your horsepowers
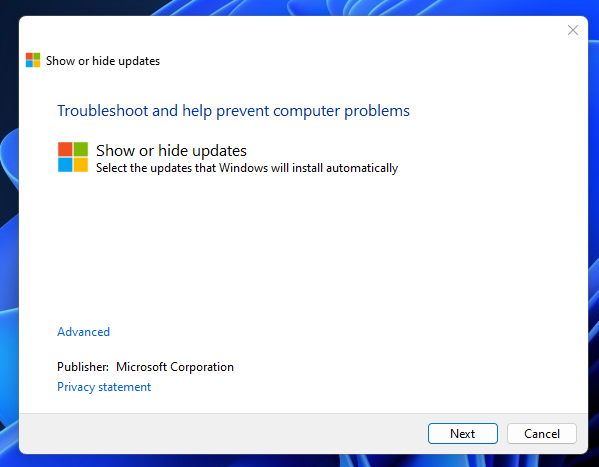
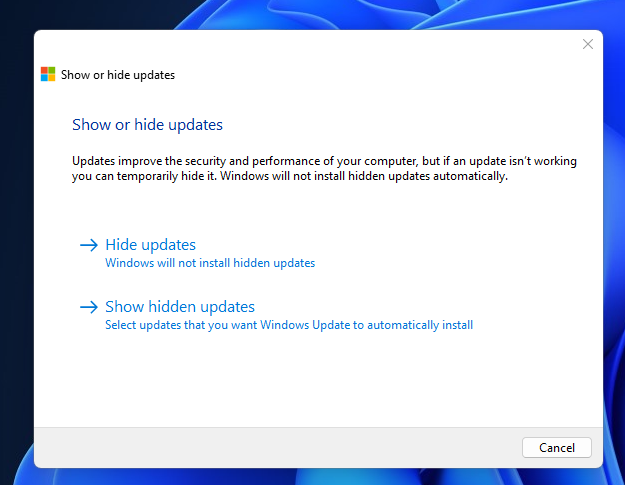
The “Windows Show or Hide Updates Troubleshooter” is a free tool Microsoft Corporation had created to hide or show Windows Updates. This repository is an archive of the troubleshooting file.
It can hide or show a specific update forever or unless you reverse your decision.
Q: Why this repository exists in the first place?
A: Microsoft had shutted down the official link of the file. Luckily, it is archived on the WayBack Machine.
Now, I had decided to create a repository for it due to its low popularity.
Q: What is the features of this troubleshooter?
A: You can hide or show Windows Updates (unless you reverse your actions) forever in a easy to use GUI.
Q: In what situation I can use this tool?
A: You can use this tool to hide buggy or problematic Windows Updates, so that the updates will never show or will install again (unless you reverse the hiding).
Q: Is the file really safe? I am worried about the safety of my computer.
A: It is 100% safe because the file is created by Microsoft themselves, it is not modified in anyway. Not convinced? You may check its safety on VirusTotal that is linked right here: https://www.virustotal.com/gui/file/8723b97b8e4ede3b5b7fd0ba129edfbc113a4db329609f0eaffe24e6a37e019e/summary/ Q: What are the minimum system requirements of this troubleshooter?
A: There are no minimum system requirements. The troubleshooter just needs Windows Vista and above, as Vista is the first OS to support the troubleshooters.
Download Link: https://github.com/thedoggybrad/wushowhide.diagcab/raw/main/wushowhide.diagcab
Note: TheDoggyBrad will assume no liabilities in anyway due to use of this troubleshooting software.
Final Note: To observe, preservation of the original file (Published by Microsoft) this repository turned into an archive on December 2, 2022. The website, the links will still work.
This project is a latest refactor of SwiftBubble, open-sourced by @nemesit. Many thanks to the great project!
According to the original author, this screensaver is inspired by the MacBook 12″ promotional video. I love this screensaver very much for quite a long time. But the original copy is not compatible with the latest MacOS Catalina/Big Sur anymore. So, I decided to refator this project in Swift 5.2.
I used the higher-resolution video in the original repository, and updated video player and layout with the latest API.
Anyway, please enjoy this screensaver.
Preview
Compile
This project is compiled with XCode 12.1. The entire XCode project is in the repo. If you would like to make changes, just clone it and compile with XCode 12, it should be fine.
Installation
Check the latest release. Unzip file bubble-screensaver.saver.zip to get bubble-screensaver.saver, double click to install.
You can interact with your device using the Ioterop Connecticut server (https://iowa-server.ioterop.com). This server can get/send commands/datas with your device and validate the way your code runs.
(* Connecticut* is the LwM2M Ioterop test server where your device will be connected. This is one solution among others (e.g.: Alaska platform, …).
Tramway is a development utility to facilitate rapid development by generating common boilerplate and providing the necessary build tools to create an application with Javascript. It includes:
Command for creating routes and controllers
Installation utility for tramway pieces
Build tools so you don’t need to configure them yourself
Installation
Generate a new project with npm init
npm install --save-dev tramway and npm install -g tramway
Documentation
Usage
Install Tramway
Build Your Project
Create API
Create Route
Create Controller
Create Service
Create Entity
Create Provider
Create Repository
Upgrade Babel
Configuration
Usage
Replace the COMMAND with the appropriate one from the table below with its corresponding arguments and options.
If installed globally:
tramway COMMAND
Otherwise:
./node_modules/.bin/tramway COMMAND
All commands that create new classes will update the corresponding index.js entries.
Install Tramway
Will install the core modules your application needs with tramway or specific pieces as specified in the arguments. It will also add the necessary files to your project, and entries to gitignore. Note, this command will modify your package.json and package-lock.json files.
Argument
Command Type
Type
Default
Required
Comments
pieces
argument
string
none
no
A list of tramway modules to install
Example:
To install the base:
tramway install
To add modules, like a MySQLProvider:
tramway install mysql
Build your project
In most projects you need to set up gulp or grunt or webpack yourself. To get you started quickly, this module includes a build command which will handle the process for you granted you follow the folder convention.
You can also add the command to your package.json scripts to continue using the familiar hooks like npm run build.
Example:
tramway build
Will run gulp tasks on your src folder and create a ready dist folder.
Start your project
In most projects you will likely set up a server to run your project with. To get you started quickly, this module includes a dev server which can watch and auto-build on changes if you specify it.
Example:
tramway start
Create API
Will create all the necessary classes and mappings to have a full API ready. The routes follow REST and are automatically mapped to their controller action with services instantiated and linked in the Dependency Injection configuration.
Argument
Command Type
Type
Default
Required
Comments
resource
argument
string
none
yes
The name of the Resource to use for all naming
provider
option
string
none
yes
Adds a provider key to the Repository declaration to link them
Example:
tramway create:api Product --provider=mysql
This command will create the following new files and update corresponding index.js files, as well as configuration files:
The upgrade babel command will replace the old setup – as per the way the Tramway (<0.5.0) initially installed it – with the new set up, upgrading babel presets to their 7.0 versions.
Example:
tramway upgrade:babel
Configuration
The commands create their files in the default scalpel that TramwayJS follows
In some projects, however, the structure can vary and the framework is able to adapt to adjustments using environment variables.
Variable
Purpose
Default
TRAMWAY_PROJECT_PATH
The root path of the project
./src
TRAMWAY_PROJECT_CONTROLLERS_PATH
Path to controllers appended to TRAMWAY_PROJECT_PATH
controllers
TRAMWAY_PROJECT_ENTITIES_PATH
Path to entities appended to TRAMWAY_PROJECT_PATH
entities
TRAMWAY_PROJECT_SERVICES_PATH
Path to services appended to TRAMWAY_PROJECT_PATH
services
TRAMWAY_PROJECT_CONNECTIONS_PATH
Path to connections appended to TRAMWAY_PROJECT_PATH
connections
TRAMWAY_PROJECT_REPOSITORIES_PATH
Path to repositories appended to TRAMWAY_PROJECT_PATH
repositories
TRAMWAY_PROJECT_PROVIDERS_PATH
Path to providers appended to TRAMWAY_PROJECT_PATH
providers
TRAMWAY_PROJECT_CONFIG_PATH
Path to config appended to TRAMWAY_PROJECT_PATH
config
TRAMWAY_PROJECT_ROUTES_FILE
Name of the routes file storied in the config directory
routes
TRAMWAY_PROJECT_SERVICES_FILE
Name of the services file storied in the config directory
services
Example:
TRAMWAY_PROJECT_PATH=./dev tramway create:service Service
This command will create a new Service.js file in ./dev/services. It has the same behavior as overriding the dir using the dir option but is meant for a global application.
#leafy_values (Hash) returns a hash representation of your fields data
#leafy_values= allows you to assign custom attributes data
#leafy_fields_values (Leafy::FieldValueCollection) returns a collection of Field::Value instances which provide more control over values data
Please note:
Leafy is stateless and changing Schema instance won’t reflect on your active record model instance.
For changes to take place you have to explicitly assign schema or attributes data to the model.
If you get a NameError: uninitialized constant in Rails, please ensure you have required leafy in an initializer.
in app/config/initializers/leafy.rb simply add require 'leafy'
classMyLovelyCoderdefdump(data)"lovely_#{data}"enddefload(data)data.split("_")[1]endendLeafy.configuredo |config|
# you may wonna use oj insteadconfig.coder=MyLovelyCoder.newend
Adding your own types
Leafy allows adding your own data types
To allow leafy process your own data type you need to describe how to store it. For that purpose leafy utilizes converter classes associated for each type.
Converter instance has to implement #dump and #load methods
the email field is mandatory;
the email field must have a valid email address;
the password field is mandatory;
the password field must be at least 6 characters long.
endpoint POST /user
-> The request return status 200 and a token if user was created with success
-> The body of the request should follow the format below:
endpoint GET /user
-> The request return status 200 and all users in database
-> The request header must be contains a valid token
endpoint GET /user/:id
-> Return a user according to id
-> The request header must be contains a valid token
endpoint POST /categories
-> Add a category.
-> The body of the request should follow the format below:
{
"name": "Go Lang"
}
-> The validation rules are:
the name field is mandatory;
endpoint GET /categories
-> Return all categories.
-> The request header must be contains a valid token
endpoint POST /post
-> Add a blog post
-> The request header must be contains a valid token
-> The body of the request should follow the format below:
{
"title": "Latest updates, August 1st",
"content": "The whole text for the blog post goes here in this key",
"categoryIds": [1, 2]
}
endpoint GET /post
-> Return all blogs post, user owner of it and database categories
-> The request header must be contains a valid token
endpoint GET /post/:id
-> Return a blog post, user owner of it and database categories according to id
-> The request header must be contains a valid token
endpoint PUT /post/:id
-> Update a blog post
-> The request header must be contains a valid token
-> The body of the request should follow the format below:
{
"title": "Latest updates, August 1st",
"content": "The whole text for the blog post goes here in this key"
}
endpoint DELETE /post/:id
-> Delete a blog post
-> The request header must be contains a valid token
-> Only the blog post creator can delete it
endpoint DELETE /user/me
-> Delete you from the database, based on the id in your token
-> The request header must be contains a valid token
endpoint GET /post/search?q=:searchTerm
-> Return an array of blog posts that contain in their title or content the term passed in the URL
-> The request header must be contains a valid token
-> The query params of the request should follow the format below:
The English version of the document can be found here.
Обновления
01.11
Мы выкладываем пример данных, аналогичных private test по HTR (ссылка). В данном примере 200 сэмплов, одна половина из которых – на английском, другая половина – на русском. В приватной части датасета перевернутых изображений не будет.
28.10:
Напоминаем, что в public test есть изображения, повернутые на 90 градусов против часовой стрелки. В private test, однако, таких изображений не будет. По ссылке находится архив, который содержит файл rotate.json – список изображений из public test, которые нужно повернуть на 90 градусов по часовой стрелке. Пример использования этого файла приведен в скрипте rotate.py внутри архива. Вы можете вставить подгрузку этого json’а в свой скрипт с решением, чтобы повернуть нужные изображения. Это повлияет только на значение метрики публичного лидерборда – для выборки на private test скрипт бесполезен, так как в ней не будет изображений с вертикальной ориентацией. В представленном для обучения датасете русских тетрадей, как и в IAM, нет повернутых изображений, поэтому, как нам кажется, специально учить модель переворачивать изображения смысла нет.
27.10:
В раздел Пример решения добавлена ссылка на актуальный пример сабмита, а также ссылки на примеры входных/выходных данных.
Уточнения по подзадаче HTR: по ссылке из раздела Пример решения можно скачать тестовый датасет, в котором содержатся собранные и размеченные нами изображения с текстом из школьных тетрадей (на русском и английском языках). Подчеркнем, что в test public, помимо стандартных, содержатся примеры с вертикальной ориентацией (повернутые на 90 градусов). Распределение данных в датасете рукописных тетрадей на английском языке отличается от распределения предлагаемого нами для обучения датасета IAM, поэтому советуем применять различные виды нормализации, аугментации – и учиться не только на IAM.
В раздел Данные задачи VQA добавлена ссылка на набор данных, представляющий собой подвыборку VQA v2 (train), которая пересекается с обучающей выборкой Visual Genome, – это вопросы с ответами (на русском и английском языках) для 33,821 изображений.
Общее описание задачи
В рамках данной задачи предлагается построить единую multitask-модель, которая бы успешно решала такие относящиеся к различным модальностям подзадачи, как Code2code translation (С2С), Handwritten Text Recognition (HTR), Zero-shot object detection (zsOD), Visual Question Answering (VQA) – и сумела бы превзойти минимальное значение интегральной метрики, установленное Организатором, а также минимальные значения метрик по каждой из подзадач.
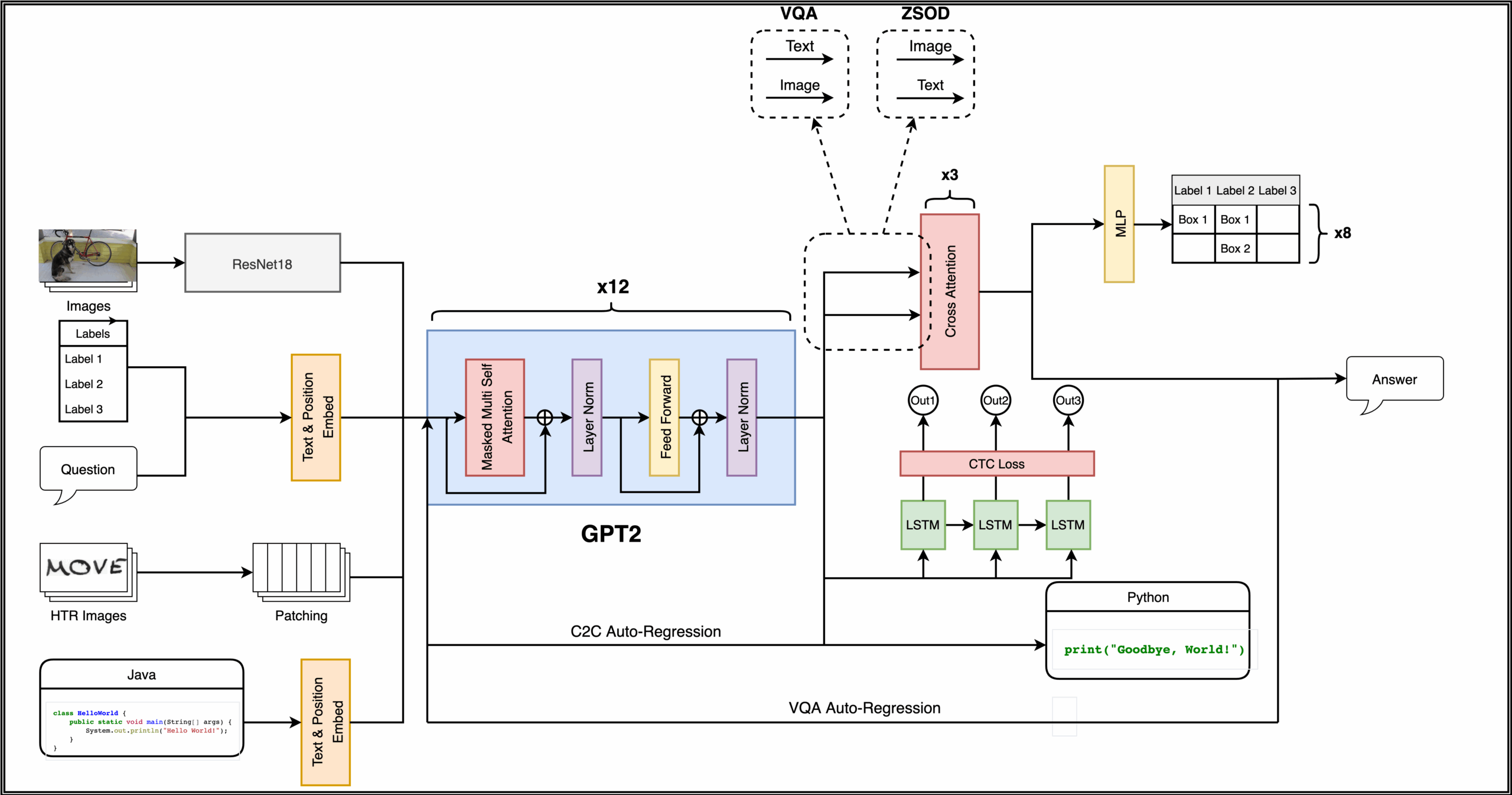
Мы предоставляем концепт единой модели, которая обучается на нескольких задачах, относящихся к различным модальностям (визуальной, аудио и текстовой). Концепт вдохновлен статьёй “Pretrained Transformers as Universal Computations Engines” (Lu et al., 2021), в которой исследуется способность предобученных языковых моделей на базе архитектуры Трансформер формировать качественные репрезентации для произвольных последовательностей данных – обобщаться, таким образом, на другие модальности с минимальным дообучением. Основа предлагаемой в концепте архитектуры – предобученная языковая модель GPT-2; эксперименты проводятся как с “замороженной” моделью (Frozen Pretrained Transformer), так и с моделью, все слои которой дообучаются на трёх модальностях одновременно.
Для того чтобы представленная командой/участником архитектура считалась единой (multitask-модель), необходимо и достаточно выполнения следующих требований:
общие параметры (shared weights) должны составлять не менее 25% всех параметров модели: если – суммарное число параметров моделей, решающих 4 подзадачи, а – число общих параметров этих моделей (то есть одинаковых и по значению, и архитектурно), тогда необходимо, чтобы
общие параметры не должны иметь исключительно номинальный характер — напротив, должны значимым образом использоваться во время совершения предсказания моделью и положительно влиять на качество её работы.
При невыполнении хотя бы одного из требований выше модель считается решающей подзадачу (или подзадачи) по отдельности.
Загрузка решений станет доступна с 07.10.2021.
Общий формат решения
Содержимое контейнера
В проверяющую систему необходимо отправить код алгоритма, запакованный в ZIP-архив. Решения запускаются в изолированном окружении при помощи Docker. Время и ресурсы во время тестирования ограничены. Участнику нет необходимости разбираться с технологией Docker.
В корне архива обязательно должен быть файл metadata.json следующего содержания:
Здесь image – поле с названием docker-образа, в котором будет запускаться решение, entrypoint – команда, при помощи которой запускается скрипт инференса. Для решения текущей директорией будет являться /home/jovyan.
Для запуска решений можно использовать существующее окружение:
При необходимости вы можете подготовить свой образ, добавив в него необходимое ПО и библиотеки (см. инструкцию по созданию docker-образов); для использования его необходимо будет опубликовать на sbercloud. Кастомные образы должны быть наследованы от базовых образов sbercloud (см. базовые образы). При создании кастомного образа необходимо присвоить ему индивидуальное название и тэг (например, my_custom_fusionchallenge:0.0.5).
Структура данных
В контейнер помещается папка input. Названия вложенных в input подпапок соответствуют названиям подзадач, которые необходимо решить единой модели. Внутри каждой из подпапок (C2C, HTR, zsOD, VQA) лежит контент, необходимый для совершения предсказаний.
Структура данных выглядит следующим образом:
input
C2C
requests.json
HTR
images
zsOD
images
requests.json
VQA
images
questions.json
Единая модель должна сформировать предсказания формата prediction_{TASK_NAME}.json для каждой из подзадач, то есть после инференса модели должно получиться 4 файла: prediction_C2C.json, prediction_HTR.json, prediction_zsOD.json, prediction_VQA.json. Эти файлы должны располагаться в папке output (полный путь: /home/jovyan/output).
Структура директории с предсказаниями модели должна быть следующей:
output
prediction_C2C.json
prediction_HTR.json
prediction_zsOD.json
prediction_VQA.json
После этого в контейнер подкладываются правильные ответы формата true_{TASK_NAME}.json и запускается скрипт подсчета метрик для каждой из подзадач. Финальная метрика считается как сумма метрик для каждой из подзадач (об этом ниже).
Бейзлайн
В папке fb_baseline находится базовое решение по всем четырем подзадачам. Это решение основано на концепте мультимодальной модели из fb_concept. В ноутбуке fb_baseline/FBC_baseline.ipynb находится код с формированием датасета, архитектурой модели и логикой обучения. В папке fb_baseline/fb_utils – вспомогательный набор скриптов.
BLEU.py и c2c_eval.py – скрипты, в которых содержатся вспомогательные функции для инференса и расчета метрики в задаче C2C
detection_vqa.py – скрипт, в который вынесены функции потерь, слои feedforward и cross-attention, а также вспомогательные функции для задач zsOD и VQA
download.py – скрипт загрузки файлов для обучения
handwritten.py – скрипт с вспомогательными функциями для задачи HTR
metrics.py – подсчет метрик всех 4-х подзадач.
На следующем рисунке представлена схема предлагаемой архитектуры:
По этой ссылке можно посмотреть запись вебинара с подробным разбором бейзлайна.
Пример решения
По ссылке находится архив sberai_baseline_ooc.zip, в котором содержится пример загружаемого решения. Метрику качества данного решения можно найти в лидерборде соревнования по названию команды sberaiooc. Следующие файлы в загружаемом архиве необходимы для формирования предсказаний модели:
metadata.json – обязательный файл для каждого решения; в нём должны быть указаны пути к образу и скрипту выполнения модели
run.py – основной скрипт для инференса модели
last.pt – веса модели, которые подгружаются во время исполнения скрипта run.py
utils – папка с вспомогательными скриптами для run.py. В случае бейзлайна содержит два файла:
dataset.py – в скрипт вынесен код для формирования класса DatasetRetriever и функция fb_collate_fn
fb_model.py – в скрипт вынесен весь код для создания класса модели
gpt_init – папка с необходимыми файлами для инициализации GPT2Tokenizer и GPT2Model
fb_utils – вспомогательный набор скриптов; повторяет, за некоторыми исключениями, аналогичную папку из fb_baseline в данном репозитории.
Примеры данных (советуем обратить внимание на input/HTR/images: дополнительно к русскому языку там содержатся примеры на английском):
input – примеры входных данных для каждого из заданий;
output – примеры предсказаний модели для файлов из папки input; это случайные предсказания, и они указывают только на верный формат, который ожидается от модели участников;
true – примеры файлов с верными ответами для каждой задачи, с ними сравниваются предсказания из папки output во время подсчета метрики.
Ограничения
В течение одних суток Участник или Команда Участников может загрузить для оценки не более 3 (трёх) решений. Учитываются только валидные попытки, получившие численную оценку.
Контейнер с решением запускается в следующих условиях:
100 Гб оперативной памяти
3 vCPU
1 GPU Tesla V100 (32 Гб)
время на выполнение решения: 90 минут
решение не имеет доступа к ресурсам интернета
максимальный размер упакованного и распакованного архива с решением: 10 Гб
максимальный размер используемого Docker-образа: 15 Гб.
Мы предоставляем участникам возможность получить доступ к вычислительным ресурсам Кристофари для обучения модели. Количество ресурсов ограничено. Для получения доступа необходимо отправить заявку на адрес Christofari_AIJContest_2021@sberbank.ru с описанием того, как именно планируется использовать вычислительные ресурсы.
Метрика качества
С метрикой качества для каждой из подзадач можно ознакомиться по ссылке.
Подзадача 1 – Code2code Translation
Описание
Задача перевода с одного языка программирования на другой, стандартно входит в обширный репертуар сферы ML4Code. На данный момент существует несколько различных вариантов решения – как в духе контролируемого обучения, при котором в качестве обучающего датасета используется параллельный корпус (базовая модель бенчмарка CodeXGLUE c CodeBERT в качестве кодировщика в архитектуре типа «кодировщик-декодировщик», Lu et al., 2021 ), так и неконтролируемого, включающего предобучение кросс-лингвальной языковой модели на монолингвальных корпусах (TransCoder, Lachaux et al., 2020).
Особую сложность представляет случай, когда язык-источник и целевой язык имеют различную типизацию. Наша задача относится именно к такому варианту: необходимо выполнить перевод с языка, имеющего статическую типизацию (Java), на язык с динамической типизацией (Python). На вход модели подаётся функция, написанная на языке Java, – модель должна выдать аналогичную функцию на языке Python.
Данные
Train. В качестве обучающего датасета предлагается использовать train (5,937 программистских задач) и val (845) части параллельного корпуса AVATAR, состоящего из пар аналогичных функций/программ, одна из которых написана на языке программирования Java, другая — на Python. В связи с тем, что в датасете содержится от 1 до 5 вариантов решения задач на обоих языках программирования, можно сформировать от 1 до 25 параллельных примеров на каждую задачу. Авторы датасета предлагают выбирать для каждого языка максимум 3 решения — таким образом, на одну проблему приходится максимум 9 обучающих примеров. Мы предлагаем использовать датасет, который сформирован именно таким способом.
Файл имеет формат jsonl с полями “java” и “python”:
{"java":"import java . util . Scanner ; \u00a0 public class A1437 { \u00a0 public static void main ( String [ ] args ) { Scanner in = new Scanner ( System . in ) ; int T = in . nextInt ( ) ; for ( int t = 0 ; t < T ; t ++ ) { int L = in . nextInt ( ) ; int R = in . nextInt ( ) ; boolean possible = R < 2 * L ; System . out . println ( possible ? \" YES \" : \" NO \" ) ; } } \u00a0 }\n","python":"t = int ( input ( ) ) NEW_LINE ans = [ ] NEW_LINE for i in range ( t ) : l , r = [ int ( x ) for x in input ( ) . split ( ) ] NEW_LINE if ( 2 * l ) > r : NEW_LINE INDENT ans . append ( \" YES \" ) else : NEW_LINE ans . append ( \" NO \" ) NEW_LINE DEDENT for j in ans : print ( j ) NEW_LINE\n"}
Для создания обучающего параллельного корпуса также можно использовать CodeNet, в котором содержатся решения 4,000 программистских задач на С++, С, Python и Java, извлеченных с сайтов AtCoder (в датасете AVATAR используются решения с этого ресурса по части задач) и AIZU Online Judge. Для удобства участников мы предоставляем архив (полные данные содержатся в репозитории https://developer.ibm.com/technologies/artificial-intelligence/data/project-codenet/), в котором содержатся решения с CodeNet на языках Java и Python, разбитые по задачам. Стоит, однако, учитывать, что решения одной программистской задачи на разных языках являются, как минимум, клонами 4 типа (сохранение семантики кода при широкой вариативности синтаксиса), но не являются гарантированно идентичными друг другу с поправкой на различия в языках (буквальным переводом).
Test public. Публичный лидерборд формируется по результатам проверки предсказаний моделей на тестовой выборке (1,699 примеров) датасета AVATAR.
Test private. Приватный тестовый датасет скрыт от участников. Его формат аналогичен публичной тестовой выборке.
Формат решения
Данные для совершения предсказания, относящегося к данной подзадаче, включают:
Файл requests.json. Это словарь формата { "0": "import java . util . Scanner ; ..." , ... }. Ключами являются индексы примеров, значениями – строки функций/программ на языке Java, которые необходимо перевести на язык программирования Python.
Модель участника должна перевести все примеры из файла requests.json и сгенерировать файл prediction_С2С.json. Это словарь формата { "0": "def find ( x , par ) : NEW_LINE INDENT if par [ x ] == x : ..." , ... }. Ключами являются индексы примеров, значениями – переводы функций/программ на язык Python. Обратите внимание, что, поскольку в Python используются отступы для идентификации логических блоков в коде, в строке перевода на Python присутствуют специальные токены INDENT, DEDENT.
После проведения инференса скрипт подсчета метрик сравнивает файлы prediction_С2С.json и true_С2С.json, а затем выводит финальное значение метрики CodeBLEU.
Подзадача 2 – Handwritten Text Recognition
Описание
Перед участниками ставится задача распознавания рукописного текста на изображении. На вход модели подается изображение с рукописным текстом на русском или английском языках. Модель должна выдать в качестве ответа текстовую строку, соответствующую контенту изображения, – в данном случае строку «последовал»:
Данные
Train. Для обучения предоставляется набор данных, состоящий из собранных вручную и обработанных нами школьных тетрадей. Изображения в нем являются отдельными словами на русском языке в тексте, написанном на странице тетради. Что касается рукописных слов на английском языке, мы рекомендуем использовать известный датасет IAM.
Test public. Публичный лидерборд рассчитывается на датасете тетрадей, содержащих русские и английские рукописные слова (14,973 примера).
Test private. Приватный тестовый датасет скрыт от участников. Это тоже набор данных для распознавания текста, в похожем на обучающий датасет формате.
Формат решения
Данные для совершения предсказания, относящегося к данной подзадаче, включают:
Папка images. Это набор изображений, по которым нужно сделать предсказания. Внутри лежат файлы формата 0.png, 1.png .... Каждый файл содержит графические изображения символов, которые необходимо перевести в текстовые символы (текстовые строки).
Модель участника должна сделать предсказания на всех изображениях из папки images, и сгенерировать файл prediction_HTR.json. Это словарь формата {"0.png": "<предсказанный текст на изображении>" , "1.png": "<предсказанный текст на изображении>" , ... }. Ключами являются соответствующие названия файлов из папки images, значениями — предсказанные строки на соответствующих изображениях. Если по каким-то причинам на файле с изображением name.png не было сделано предсказания, то есть в ключах словаря prediction_HTR.json отсутствует ключ "name.png", то перевод заполняется пустой строкой "".
После проведения инференса скрипт подсчета метрик сравнивает файлы prediction_HTR.json и true_HTR.json, а затем выводит финальное значение метрики по данной задаче.
Файл true_HTR.json имеет формат { "0.png": "<правильный текст на изображении>" , "1.png": "<правильный текст на изображении>" , ... }. Ключами являются соответствующие названия файлов из папки images, значениями — правильный перевод строки на соответствующем изображении.
Подзадача 3 – Zero-shot Object Detection
Описание
Необходимо определить верное описание объекта, изображенного на фотографии (или объектов, если их несколько). Например, на фотографии могут оказаться такие сущности/объекты, описанные на естественном языке как “зеленое яблоко, лежащее на земле”, “мужчина, перепрыгивающий через гидрант”, “женщина в шортах”.
Одновременно с этим нужно определить местоположение и масштаб каждого из объектов на фотографии. Местоположение объекта описывается так называемым bounding box (ограничивающая рамка, bbox). Это прямоугольник, который наиболее аккуратно нарисован вокруг рассматриваемого объекта. Положение прямоугольника задается 4-мя числами – X, Y, W, H:
X – горизонтальная координата верхнего левого угла
Y – вертикальная координата верхнего левого угла
W – ширина прямоугольника
H – высота прямоугольника
Предсказаниями модели должны быть координаты bbox и класс, представляющий собой описание на естественном языке, для каждого объекта на фотографии. Пример результата работы модели object detection представлен на следующем изображении:
В рамках нашего соревнования задача сформулирована как zero-shot object detection. Zero-shot в описании задачи означает, что модели нужно сделать предсказание на данных, совершенно отличных от обучающего набора. Стандартная модель object detection во время предсказания должна выдавать один класс из ограниченного набора, четко заданного во время обучения модели. Zero-shot модель должна уметь детектировать классы, которые не встречались в обучающей выборке.
Еще одна особенность предлагаемой задачи заключается в том, что множество классов для каждого изображения передается в формате запроса. Запрос может содержать описания как на русском, так и на английском языках.
Во время стадии предсказания на вход модели подаются две сущности: первая – изображение, вторая – запрос на естественном языке. Формат запроса – список текстовых строк, которые представляют собой описания на естественном языке – классы, среди которых нужно произвести поиск. Пример: «красное яблоко, висящее на ветке», «лысый человек», «девочка, кормящая слона». Запрос содержит и верные описания, которые относятся к объектам, действительно присутствующим на изображении, – и некоторое количество неправильных описаний. Их объединение является общим пространством поиска для модели. Результатом предсказания модели должен стать список предсказанных классов вместе с соответствующими координатами bounding box.
Данные
Train. Для обучения предлагается использовать популярный датасет MS-COCO, содержащий изображения (файл 2017 Train images) и соответствующие им аннотации (файл 2017 Train/Val annotations).
Также стоит использовать датасет VisualGenome, за исключением изображений, которые включены в выборку публичного тестового датасета (чтобы результаты публичного лидерборда были показательны для участников).
Мы также предоставляем набор данных, представляющий собой подвыборку VisualGenome (train), которая пересекается с обучающей выборкой VQA v2, – это region descriptions (в среднем 10 описаний на 1 изображение) с соответствующими ограничивающими рамками для 33,821 изображений; половина семплов дана на английском языке, другая половина – на русском языке (машинный перевод). По ссылке находится маппинг из идентификаторов изображений в VisualGenome в идентификаторы COCO (и VQA v2, соответственно).
Test public. Публичный тестовый датасет сформирован из части датасета VisualGenome (1,000 примеров); набор классов в нем скрыт от участников. В качестве позитивных классов используются region descriptions (описания подвергаются нормализации: приведению к нижнему регистру, удалению непечатаемых символов и т.п.; объединяются под единым описанием боксы, относящиеся к одной сущности) из VisualGenome; негативные классы формируются заменой некоторых объектов/атрибутов в описании на те, которые отсутствуют на фото: например, the chair is grey заменяется на the chair is pink, cushion on the end of the sofa – на cushion on the end of the table; также в качестве негативных примеров используются описания объектов, относящиеся к тому же домену, что и верные классы: если на фото изображена улица, то в качестве негативных примеров могут присутствовать, например, такие описания, как tall green bricks wall, shingled home in distance, food stand in the street (при условии, конечно, что описанные объекты отсутствуют на фотографии).
Test private. Приватный тестовый датасет скрыт от участников, так же как и набор классов в нем.
Формат решения
Данные для совершения предсказания, относящегося к данной подзадаче, включают:
Папка images. Это набор изображений, по которым нужно сделать предсказания. Внутри лежат файлы формата 0.jpg, 1.jpg ....
Файл requests.json. Это словарь формата { "0.jpg": ["красное яблоко, висящее на ветке", "лысый человек", "девочка, кормящая слона"] , ... }. Ключами являются соответствующие названия файлов из папки images, значениями – список классов, которые нужно детектировать на соответствующем изображении (запрос). Как говорилось ранее, список классов может быть как на русском, так и на английском языке. Запрос, таким образом, представляет собой список классов (описаний на естественном языке), среди которых нужно произвести поиск. Список классов содержит и правильные описания, относящиеся к объектам, которые действительно находятся на изображении, и некоторое количество неправильных описаний (соответствующих объектов нет на изображении).
Модель участника должна сделать предсказания на всех изображениях из папки images, и сгенерировать файл prediction_zsOD.json. Это словарь формата {"0.jpg": {"красное яблоко, висящее на ветке": [[473.07, 395.93, 38.65, 28.67]], "лысый человек": [], "девочка, кормящая слона": [[0.0, 101.15, 452.3, 319.43], [10.0, 123.0, 15.0, 22.0]]}, ... }. Ключи – названия файлов с изображениями из папки images, значения – словари, ключи в которых являются названиями классов, предложенных в requests.json для поиска на соответствующем изображении, а значения, в свою очередь, – предсказания модели для соответствующего класса на данном изображении. Предсказания для каждого класса внутри каждого изображения должны содержать координаты ограничивающих рамок: по ключу “название файла с изображением” – вложенный словарь классов. Внутри каждого такого словаря по ключу названия класса — вложенный список формата [[xmin, ymin, w, h]]. Формат одного элемента в списке: [473.07, 395.93, 38.65, 28.67] (четыре элемента, разделенных запятыми) – координаты bbox в формате xywh. Во вложенном списке может содержаться неограниченное количество элементов – это все боксы, которые предсказала модель для данного класса на данном изображении.
Словарь правильных ответов true_OD.json, который будет использоваться для оценки качества модели во время запуска в контейнере, имеет следующий формат: {img_name: {class_name1: [[xmin, ymin, w, h]], class_name2 :[], class_name3 : [[xmin, ymin, w, h], [xmin, ymin, w, h]]}, ...}. Если по ключу класса находится пустой список, это значит, что данный класс в запросе из requests.json является негативным, то есть описанный объект отсутствует на изображении. Модель так же не должна ничего предсказывать для данного лейбла, то есть должен быть передан пустой список [].
Далее система сравнивает файл с предсказаниями с файлом true_zsOD.json, содержащим правильные ответы, и выводит итоговую метрику F1-score.
Подзадача 4 – Visual Question Answering
Описание
Необходимо ответить текстом на вопрос по представленному изображению. На вход модели подаются изображение и текстовый вопрос, связанный с этим изображением, – на выходе модель должна выдать ответ на заданный вопрос в виде текста. Например, ответом на вопрос “Из чего сделаны усы?” в данном случае может быть слово “бананы”:
Особенность задачи заключается в том, что вопросы не гомогенны: подходящий ответ может как состоять из нескольких слов, так и быть односложным (ответ типа “да/нет”) или представлять собой число. Подразумевается, что на один вопрос необходимо дать только один ответ.
Вопросы могут быть как на английском языке, так и на русском. Предполагается, что язык ответа соответствует языку вопроса, кроме тех случаев, когда вопрос касается текста на изображении (например, “Что написано на футболке?”) – в этом случае ответ должен быть на том же языке, на котором написан текст.
Данные
Train. В качестве обучающей выборки предлагается использовать часть train датасета VQA v2: в состав входят вопросы на английском языке (файл Training questions 2017 v2.0), изображения из датасета COCO, по которым эти вопросы заданы (файл Training images), а также аннотации — ответы на вопросы (файл Training annotations 2017 v2.0).
Мы также предоставляем набор данных, представляющий собой подвыборку VQA v2 (train), которая пересекается с обучающей выборкой Visual Genome, – это вопросы с ответами для 33,821 изображений; для половины изображений вопросы даны на английском языке (90,359 вопросов), для другой половины – на русском языке (88,761 вопрос, машинный перевод).
Test public. Публичный тестовый датасет состоит из вопросов как на русском, так и на английском языках: русскоязычная часть представляет собой переведённые примеры из первых 10 тыс. семплов валидационной части датасета VQA v2, английская — примеры из вторых 10 тыс. того же датасета, взятых в оригинальном виде. Общий размер выбоки – 5,446 примеров.
Test private. Приватный тестовый датасет скрыт от участников. Его формат аналогичен публичной тестовой выборке, в нем присутствуют вопросы на русском и английском языках.
Формат решения
Данные для совершения предсказания, относящегося к данной подзадаче, включают:
Папка images. Это набор изображений, к которым относятся вопросы. Внутри лежат файлы формата 0.jpg, 1.jpg ....
Файл questions.json. Это словарь формата { "0": {"file_name": "1.jpg", "question": "Куда он смотрит?"} , ... }. Ключами являются индексы примеров, значениями – словарь с полями “file_name” (значение – название файла из папки images) и “question” (значение – текст вопроса по соответствующему изображению). Вопросы могут быть заданы как на английском языке, так и на русском.
Модель участника должна сделать предсказания по всем вопросам и сгенерировать файл prediction_VQA.json. Это словарь формата { "0": "вниз" , ... }. Ключами являются индексы примеров, значениями – предсказанные моделью ответы на соответствующие вопросы.
После проведения инференса скрипт подсчета метрик сравнивает файлы prediction_VQA.json и true_VQA.json, а затем выводит финальное значение метрики Accuracy.
Интегральная метрика
Итоговая оценка multitask-модели складывается из оценок по подзадачам:
где S – итоговая оценка участника, S1 – оценка по подзадаче Code2code Translation, S2 – оценка по подзадаче Handwritten Text Recognition, S3 – оценка по подзадаче Zero-shot Object Detection, S4 – оценка по подзадаче Visual Question Answering.
Оценка по каждой из подзадач принимает значения от 0 до 1 (исключение составляет метрика CodeBLEU, которая используется для оценки Code2code Translation и может принимать значения в диапазоне от 0 до 100 – с целью нормализации метрика умножается на коэффициент 0.01) – таким образом, минимальное значение итоговой оценки составляет 0, максимальное – 4. Расчет оценки по каждой подзадаче округляется до третьего знака после запятой. По значениям итоговой оценки формируется лидерборд по задаче Fusion Brain Challenge.
Призовой фонд
Размер возможного выигрыша зависит от того, является ли предложенная архитектура единой multitask-моделью (в которой доля общих параметров, используемых для решения всех подзадач, составляет не менее 25% от всех параметров) или unitask-моделью (решающей одну подзадачу).
В случае multitask-модели, для каждого призового места есть фиксированная сумма выигрыша (FIX). Размер бонуса зависит от итоговой оценки призеров, но не может превышать разницы между максимальным значением (MAX) и фиксированным. Необходимо превзойти минимальные значения метрик, установленные для каждой подзадачи, — и, следовательно, минимальное значение интегральной метрики.
Минимальные оценки, установленные по каждой из подзадач, имеют следующие значения:
Минимальное значение интегральной оценки Smin рассчитывается таким образом:
Формула расчета денежного приза имеет следующий вид:
где S – итоговая оценка участника, Smin = 0.85 – минимальное значение итоговой оценки, коэффициент α зависит от места в лидерборде (топ-3 решения) и вычисляется следующим образом:
где αplace – коэффициент для расчета бонуса для первого, второго и третьего мест в лидерборде (α1 = 1.379, α2 = 0.689, α3 = 0.413) при Smin ≤ S < 2.3. MAXplace – максимальный размер вознаграждения для топ3-решений в лидерборде при S ≥ 2.3 (MAX1 = 3 млн руб., MAX2 = 1.5 млн руб., MAX3 = 0.8 млн руб.). FIXplace – фиксированная сумма выигрыша для топ-решений в лидерборде при Smin ≤ S < 2.3 (FIX1 = 1 млн руб., FIX2 = 0.5 млн руб., FIX3 = 0.2 млн руб.).
Номинации, относящиеся к созданию multitask-модели:
Первое место: от 1 000 000 рублей до 3 000 000 рублей (в зависимости от качества представленного участником решения)
Второе место: от 500 000 рублей до 1 500 000 рублей (в зависимости от качества представленного участником решения)
Третье место: от 200 000 рублей до 800 000 рублей (в зависимости от качества представленного участником решения)
Дополнительные номинации:
Организатором будут оцениваться лучшие решения по каждой из подзадач, за которые участник/команда участников, показавшая лучший результат, сможет также получить Приз, независимо от того, является ли представленная модель multitask (решающей все подзадачи единой архитектурой) или unitask (решающей одну подзадачу). По каждой из подзадач лучшее решение будет выбрано на основе лидерборда по этим подзадачам; представленная модель должна превосходить минимальное значение метрики по соответствующей подзадаче (минимальные значения описаны выше).
300 000 рублей за первое место в подзадаче Code2code Translation
300 000 рублей за первое место в подзадаче Handwritten Text Recognition
300 000 рублей за первое место в подзадаче Zero-shot Object Detection
300 000 рублей за первое место в подзадаче Visual Question Answering

































{kind=link}